
Get an introduction into generative AI, its capabilities, limitations, and common use cases like writing, reading, and chatting. You’ll understand how generation AI projects are built, including project lifecycle and technology options like prompting, retrieval augmented generation (RAG), and fine-tuning. Get a closer look into how generative AI impacts business and society, as Andrew methodically breaks down jobs into tasks for automation and augmentation opportunities. Several societal anxieties are valid, and one must note the importance of developing and using AI ethically, ensuring fairness, transparency, privacy, security, and ethical use. AI has broad applications, and can tackle significant issues like climate change, but more importantly, it can make intelligence accessible and affordable for everyone, readily providing expert advice and education.
Actionable takeaways and thoughts
- Try out for yourself how generative AI tools such as ChatGPT from OpenAI and Gemini (previously Bard) from Google or Bing Chat from Microsoft
- This course gives a superb overview of Generative AI, and gives a rich perspective into how it can be used in business and the impact on our everyday working lives. Highly recommend.
Generative AI for Everyone summary
This is my online learning course summary for Generative AI for everyone by Andrew Ng. The course is not lengthy (3 weeks total), but covers many definitions that were new to me and while I have tried to make this summary concise, it will include all new concepts, which in my opinion will richly enhance your understanding of generative AI, vital to making the most of this course. Prior to this course, I am a daily ChatGPT user, but I never had any formal education into generative AI, so there were times I was curious to learn more about what the course introduced and went off to do more research, as you may discover below.
- Generative AI is a recent advancement in AI technology that works alongside supervised learning, which is foundational for labeling tasks.
- Supervised learning is a crucial AI tool that maps inputs (A) to outputs (B), enabling applications like spam filters, online advertising, medical diagnoses, and sentiment analysis.
- The 2010-2020 decade highlighted that AI models’ performance improves with larger data sets and computational power, setting the stage for generative AI.
- Large language models (LLMs), like ChatGPT, generate text by predicting the next word in a sequence, trained on vast amounts of text data to produce contextually relevant outputs.
- LLMs use supervised learning to repeatedly predict the next word, transforming sentences into training data that helps the model learn word prediction.
- People find LLMs useful for writing assistance, information retrieval, and as thought partners in various work-related tasks.
- Supervised learning is a type of machine learning approach. The goal in supervised learning is to make predictions from data. The algorithm learns from labelled data, meaning the input data is paired with corresponding output labels. After training, it will be evaluated on a separate data test set, to test its performance on unseen data. With keen accuracy, recall and precision and other metrics, it can then make predictions on new, unseen data. Some examples:
- Spam filters in email – automatically filtering out unwanted emails from reaching the inbox
- Online advertising – conversion/ctr prediction, ad targeting and specialisation, ad creative specialisation, the list goes on
- Self -driving cars
- Medical x rays
- Manufacturing defect inspection
- Speech recognition
- Reputation monitoring
- Recommendation engines, such as Amazon’s e-commerce store and how Netflix recommends new things to watch
- LLMs offer a novel way to find information, such as answering questions about capitals or explaining acronyms, although users should verify facts due to potential inaccuracies or “hallucinations” by LLMs.
- LLMs can assist in refining writing or generating creative content, like short stories, showcasing their ability to act as partners in brainstorming or creative processes.
- For reliable or medically sensitive information, authoritative web sources are recommended over LLMs due to their tendency to generate plausible but potentially incorrect information.
- While traditional web searches provide solid recipes or advice from reputable sources, LLMs excel in generating content for unique or unconventional queries, like a coffee-infused pineapple pie recipe, where standard information might not exist.
- AI is a general purpose technolog, comparable to electricity or the internet in its broad utility.
- Versatility in Tasks:
- Writing: Brainstorms creative suggestions such as product names.
- Answering Questions: Provides specific information like company policies with relevant data access.
- Reading for Comprehension: Processes extensive information to produce concise outputs, e.g., identifying email complaints.
- Chatbot Interactions: Facilitates both general and specialized tasks, from order taking to customer service.
- Main Applications of LLMs:
- Web Interface-Based Applications: Users interact directly with LLMs via platforms like ChatGPT or Bard.
- Software-Based LLM Applications: Integrated into broader software systems for tasks such as automated email routing.
- LLMs excel in generating creative content and specific text from prompts. Effective in brainstorming creative names and ideas to enhance sales. Capable of producing detailed written content like press releases when given sufficient context.
- Refining Prompts for Better Results:
- Importance of iterative refinement of prompts to achieve desired outcomes.
- LLMs in Translation Tasks: Competitive with traditional machine translation engines for well-represented languages. Limitations noted for less common languages, with an example in formal Hindi translation.
- “Pirate English” used creatively to assess translation quality, demonstrating a method to evaluate LLM translation effectiveness.
- Writing be done via web user interface. Start with a prompt to generate a piece of text. For example: “brainstorm 5 creative names” or “brainstorm ideas for increasing cookie sales”. Use a LLM via the web to write copy for you. E.g “write a press release announcing the hire of a new COO”. You can give it more context or background information, it will write specific and better copy for you or you get very generic answers e.g name, details, bio of person and information of the company. It doesn’t matter if you don’t get it right the first time, this is where you learn to write more effective prompts.
- Reading
- Large Language Models (LLMs) excel in both writing and reading tasks, with reading tasks involving processing prompts to generate outputs that are usually similar or shorter in length compared to the input.
- Proofreading: LLMs are effective in identifying and correcting spelling, grammatical errors, and awkward sentences in text, making them valuable tools for ensuring content quality.
- Summarization
- LLMs can summarize lengthy articles, enabling quick understanding of main points. This is useful for getting the gist of long documents without reading them in full.
- Use the prompt: Summarise the following paper in 300 words or fewer.
- Customer Service Call Summarization:
- For businesses, LLMs can summarize text transcripts of customer service calls, providing managers with concise overviews of customer interactions and issues.
- Customer Email Analysis:
- LLMs can analyze customer emails to determine if they contain complaints and decide the appropriate department for routing, enhancing efficiency in customer service management.
- Reputation Monitoring:
- LLMs can monitor customer sentiment through reviews, categorizing them as positive or negative, and assist in tracking sentiment trends over time, useful for businesses to address customer satisfaction proactively.
- LLMs can summarize lengthy articles, enabling quick understanding of main points. This is useful for getting the gist of long documents without reading them in full.
- Chatting
- General Purpose vs. Specialized Chatbots: ChatGPT, Bard, and Bing exemplify general-purpose chatbots, while there’s a trend towards specialized chatbots tailored for tasks like customer service or travel planning.
- Examples of Specialized Chatbots:
- Customer service bots for specific tasks like taking cheeseburger orders.
- Travel planning bots focused on niche areas such as budget vacations in Paris.
- Advice bots offering guidance on career choices or meal preparation.
- Actionable Bots: Some bots are designed to perform direct actions within a company’s systems, such as placing orders or facilitating IT support tasks like password resets.
- Design Spectrum for Chatbots in Customer Service:
- Humans Only: Traditional model relying solely on human agents.
- Bots Supporting Humans: Bots propose responses for human approval, offering a safety net against incorrect responses.
- Bots Triaging for Humans: Bots handle straightforward queries and escalate complex ones to humans, optimizing human agents’ focus on challenging interactions.
- Chatbots Only: A fully automated approach, eliminating human intervention in customer service.
- Deploying Bots Safely:
- Internal Testing: Initial deployment of bots in internal settings to iron out errors safely.
- Human in the Loop: Early stages include human review of bot communications for ensuring content accuracy and appropriateness.
- Direct Communication: Once bots demonstrate reliable and safe messaging, they may interact directly with customers without human oversight.
- Understanding LLM Capabilities and Limitations:
- A useful mental model for assessing what LLMs can do involves comparing tasks to what a fresh college graduate could accomplish following only prompt instructions.
- LLMs perform well on tasks that require general knowledge but struggle with tasks requiring specific, detailed knowledge about a company or individual not available in their training data.
- Specific Limitations of LLMs:
- Knowledge Cutoffs: LLMs’ knowledge is frozen at the time of their last training, meaning they lack information on events or developments occurring after that date.
- Hallucinations: LLMs sometimes fabricate information or quotes, presenting them with confidence despite their inaccuracy.
- Input and Output Length Limits: There are limitations to the length of text LLMs can process or generate in a single prompt.
- Structured Data Handling: LLMs struggle with processing structured data (e.g., tabular data in spreadsheets) effectively.
- Biases and Toxic Output: LLM training on internet text can reflect societal biases or occasionally produce toxic/harmful speech.
- Considerations for Using LLMs: It’s crucial to understand LLMs’ limitations to avoid misapplications, especially in tasks of real consequence.
- Careful prompting and awareness of biases are important when applying LLMs to ensure outputs do not perpetuate undesirable biases or harm.
- Three Main Tips for Prompting LLMs.
- Be Detailed and Specific. Provide LLMs with sufficient context or background information to complete tasks effectively. For example, giving detailed information about your qualifications for a project can help generate a more compelling request email.
- Guide the Model to Think Through Its Answer: Break down your request into clear, step-by-step instructions, especially for complex tasks. This approach can lead to more creative and accurate responses.
- Experiment and Iterate: Start with a basic prompt and refine it based on the LLM’s response. This iterative process helps hone in on the desired output.
- Prompting Process:
- Start with a clear, yet concise prompt.
- Evaluate the LLM’s response; if it’s not satisfactory, refine the prompt based on the outcome.
- Repeat the refinement process until the desired result is achieved.
- Don’t overthink the initial prompt; starting with something and iterating based on feedback is more productive.
- Caveats and Considerations:
- Be cautious with confidential information when using LLM web interfaces.
- Verify the accuracy of LLM outputs, especially for tasks with real-world consequences, to avoid relying on fabricated or incorrect information.
- General Advice:
- Prompting is a highly iterative process that involves experimenting with different phrasings and instructions to guide the LLM toward the desired outcome.
- Encouragement to try these tips on web interfaces of popular LLM providers and explore their capabilities through hands-on experimentation.
- Image generation
- Producing high quality imagery is a widely used application of generative AI. Models that generate text or images are sometimes called multimodal models.
- Image generation today is mostly done via the diffusion model method.
- Diffusion models are a type of supervised learning algorithm used for generating images. The process involves training the algorithm with a dataset containing images, such as pictures of apples, along with their corresponding descriptions or prompts.
- Training Phase: The algorithm is trained with a dataset consisting of images (e.g., an apple) and their descriptions or prompts. These images are gradually corrupted by adding noise until they become pure noise.
- Learning to Remove Noise: During training, the algorithm learns to take a noisy image as input and output a slightly less noisy image. This process is bidirectional: the algorithm is trained to generate a less noisy image from a noisy one and vice versa.
- To generate images, the algorithm can be given a completely random noise image as input. The trained algorithm then gradually removes noise from the input image, producing clearer images over multiple steps. Each step involves the algorithm learning to remove a bit more noise until the image becomes clear.
- Controlling Image Generation: While the algorithm can generate images randomly, it can also be guided by prompts or descriptions to produce specific images. By providing a prompt (e.g., “green banana”), along with a noisy image, the algorithm aims to generate a less noisy image corresponding to the given prompt. This process iterates, with the algorithm refining the image in response to the prompt until the desired image is generated (e.g., a clear image of a banana).
- In summary, diffusion models utilize supervised learning to train algorithms to generate images by removing noise from noisy inputs, either randomly or guided by prompts or descriptions. This approach allows for controlled image generation based on specified criteria.
- Applications for reputation monitoring or building a chatbot were present prior to generative AI, but now Generative AI has made these applications much easier to build and they work much better too.
- It would have taken a team of machine learning engineers to write and the process to write one would have included supervised learning. The process would begin by collecting a few hundred or thousand data points to get the label data, then finding an AI team to help train an AI model on the data, then learn how to output positive or negative depending on different inputs. Then finally find a cloud service like AWS or Google cloud or Azure to deploy and run the model.
- This process would often take months, often 6-12 months.
- However if you used a prompt based development, the timeline would be way shorter, you could deploy the model within hours or maybe days.
- This is great because the lowering of barriers to entry is leading to a flourishing more AI applications.
- The caveat, however, Generative AI tends to work better with unstructured data like texts, images and audio.
- Lifecycle of a generative AI project
- The process starts with scoping the project to define its goals, e.g., a restaurant reputation monitoring system.
- Rapid prototype development, often within days, to test concept viability.
- Iterative Development and Evaluation:
- Initial prototypes are evaluated internally to identify and correct inaccuracies, like misclassified sentiments.
- The development process is highly iterative, with ongoing improvements based on feedback.
- Deployment and External User Feedback:
- After internal confidence, the application is deployed for external use.
- Continuous monitoring to identify and correct unexpected responses from real-world usage.
- Empirical Approach to Building:
- Generative AI software development is experimental, involving trial and error to refine applications.
- Prompting is a key part of this empirical process, alongside other techniques for enhancing performance.
- Advanced Techniques for Improvement:
- For example. Retrieval Augmented Generation (RAG) which fine-tunes and pretrains models for optimizing generative AI applications.
- RAG – retrieval augment generation (source: Amazon) definition: Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
- Example: Food Order Chatbot:
- Development process involves building a prototype, internal testing, and identifying areas for improvement.
- Deployment to customers with ongoing adjustments based on their interactions and queries.
- Cost Considerations:
- Concerns about the expense of using hosted large language models are addressed, indicating cost-effectiveness.
- Conclusion:
- Provides an overview of what it feels like to develop a generative AI project, emphasizing the iterative, experimental nature of the process and the potential for widespread application development with manageable costs.
- Building Generative AI software is highly empirical. You need to consistently improve it by updating your prompt, and go again. But other than updating the prompts, there are other tools to improve the Generative AI system, for example RAG or retrieval augmented generation that gives the large language model access to external data sources. Another technique is fine tuning, and pretraining models, which refers to training an LLM from scratch.
- Cost intuition
- Costs of Using Large Language Models (LLMs):
- OpenAI/GPT3.5 charges $0.002 per 1,000 tokens.
- GPT-4 costs $0.06 per 1,000 tokens.
- Google’s PaLM 2 and Amazon’s Titan Lite are similarly inexpensive.
- Costs are primarily for output tokens, with input tokens generally being cheaper.
- Understanding Tokens:
- A token can be a word or part of a word.
- Common words count as one token; less common words may be split into multiple tokens.
- On average, one token equals about 3/4 of a word.
- Example Calculation:
- Generating text for one hour of reading (15,000 words) requires about 40,000 tokens, considering both input and output.
- At $0.002 per 1,000 tokens, generating 40,000 tokens costs about eight cents.
- Cost Intuition:
- The cost to keep someone occupied reading LLM-generated text for an hour is relatively low (e.g., eight cents).
- For high-volume or free products with millions of users, costs can add up, but for many applications, using LLMs is cost-effective.
- Comparatively, the cost is minor next to hourly wages in places like the United States, where minimum wage ranges from $10-$15 per hour.
- Costs of Using Large Language Models (LLMs):
- Introduction to Retrieval Augmented Generation (RAG):
- Retrieval augmented generation (RAG) is a technique that can expand what an LLM can do by giving it additional knowledge beyond what it has learned from the internet or other open sources.
- Enables LLMs to access and utilize proprietary documents or specific information.
- How RAG Works:
- Step 1: Searches a collection of documents for information relevant to a given question.
- Step 2: Incorporates retrieved document text into an updated prompt to provide context.
- Step 3: Prompts the LLM with this enriched prompt to generate a more accurate and informed response.
- Applications of RAG:
- Software that allows chatting with PDF files to answer questions based on the content.
- Applications that answer questions based on website articles or company-specific information.
- New forms of web search that use a chat-like interface, transforming traditional web search.
- RAG in Practice:
- Example of a workplace inquiry about parking, demonstrating how RAG can provide specific answers by referencing company policies.
- Chat with your PDF files: PandaChat, AskYourPDF, ChatPDF, and many others that let you upload your PDF file and then ask questions.
- Answer questions based on website articles, e.g Coursera Coach. Snapchat has a bot that helps to answer product related questions, and Hubspot tries to generate answers based on content from the company or the website itself.
- New forms of websearch: Google has a Generative AI feature to answer queries and so on
- Utility of RAG Across Platforms:
- Highlights the usefulness of RAG not only in software development but also when using web user interfaces of LLMs.
- Suggests copying text into the prompt of an online LLM interface as a practical application of RAG.
- LLMs don’t know everything. With RAG, we are using the LLM to be a reasoning engine, not one that just regurgitates answers by memorizing facts. This way you can expand the set of applications that an LLM can do. LLM technology is new, but it has the ability to process and reason through information.
- You can use RAG in another way, copy a piece of text into the prompt of an online web UI of an LLM and then tell it to use that context to generate an answer for me and that too can be an application of RAG (not really sure what he means).
- Introduction to Fine-Tuning LLMs:
- Fine-tuning is a technique to provide LLMs with additional information beyond initial training, useful for handling large contexts beyond input length limitations.
- It is particularly beneficial for outputting text in a specific style, though more complex to implement than RAG (Retrieval Augmented Generation).
- Pre-training Process:
- LLMs are pre-trained on vast amounts of internet data to predict the next word in sentences.
- This pre-training forms the basis for LLMs’ ability to generate text similar to what is found on the internet.
- You can make the LLM generate text that sounds relentless optimistic, for example.
- We would come up with a set of sentences or a set of texts that takes on a positive, optimistic attitude, such as “what a wonderful chocolate cake” or “the novel was thrilling”. Given texts like this, you can then create an additional dataset using “what a wonderful chocolate cake” you would have given what.
- If you gave it billions of words, and fine tune it on another 10,000 or 100,000 words, it can shift the output of the llm to take on this optimistic attitude.
- Fine-Tuning for Specific Outputs:
- Enables LLMs to learn further from a set of texts to adopt a specific tone or style, like a positive and optimistic attitude, through additional, relatively modest-sized datasets.
- Used in real applications where task definition is complex or not easily promptable, e.g., summarizing customer service calls in a detailed style or mimicking a particular writing or speaking style.
- Real world applications
- When the task isn’t easy to define in a prompt e.g if you wanted an LLM to summarize customer service calls to tell the reader about a specific problem, you could create a dataset with hundreds of examples of human expert written summaries and have an LLM that has learned from hundreds of billions of words on the internet, it will shift the LLM’s ability to write it in the style that you want!
- As it is not easy to define it in a text prompt, so fine tuning is a more precise way.
- You could ask it to mimic a writing or speaking style by fine tuning. But its not easy to describe in a prompt, so you would feed it tones of transcripts of the way someone speaks, for example
- Fine tuning can be used when prompts itself is hard to do, just by writing instructions. Fine tuning can show the LLM how to produce a more effective result.
- If you’re building an artificial character, you can get the LLM to speak in a certain style
- Another reason to fine tune is to help it gain more knowledge.
- For example, a medical doctor can write in shorthand, not in normal english, so LLM trained uin normal english will not know how to understand it. If you fed it a collection of medical writing in shorthand, it can absorb the knowledge better. Youc an then use it to build other applications on top of it to better understand medical records.
- Legal docs are another example.
- Perhaps a smaller model would have lower latency to be faster in response, and not necessarily required to have a large model (more expensive, processing 100 billion parameters, specialised computer required).
- RAG and fine tuning are relatively cheap to implement.
- Pretraining is very expensive, almost no one but large tech companies at this point are attempting this.
- Applications of Fine-Tuning:
- Enhances LLMs’ domain-specific knowledge, such as understanding medical notes, legal language, or financial documents, by training on relevant datasets.
- Allows for the optimization of smaller models for tasks that don’t require the capacity of larger models, improving performance and reducing operational costs.
- Benefits of Fine-Tuning:
- Adjusts LLMs for tasks hard to define via prompts, like achieving a specific writing style or absorbing a domain of knowledge.
- Can make smaller models perform tasks efficiently that would typically need larger models, reducing latency and cost.
- Cost of Implementation:
- Fine-tuning can be relatively inexpensive, with initial costs potentially starting from tens to hundreds of dollars, depending on the data volume for training.
- Comparison with Other Techniques:
- Fine-tuning and RAG are both cost-effective methods for enhancing LLMs, contrasting with pre-training your model, which is significantly more expensive and typically pursued by large organizations.
- Pretraining LLMs:
- Typically done by large tech companies, pretraining is expensive, often costing tens of millions of dollars, requiring extensive resources, large teams, and significant time.
- When in doubt about pretraining your own model, it’s generally advised against due to high costs.
- Contribution to AI Community:
- Open sourcing pretrained general-purpose LLMs is a valuable contribution to the AI field.
- Specialized Domains:
- Pretraining your own LLM may be beneficial for highly specialized domains with ample data, such as Bloomberg’s financial services-focused BloombergGPT.
- Alternative to Pretraining:
- For specific applications, using an existing open-sourced general-purpose LLM and fine-tuning it with your data can be more cost-effective and practical.
- Gratitude for Open Source LLMs:
- Appreciation expressed for teams that invest in pretraining and open sourcing LLMs, making a range of models available for various applications.
- Choosing an LLM:
- Model Size as a Performance Indicator:
- 1 billion parameter models excel at basic pattern matching and knowledge.
- 10 billion parameter models offer greater world knowledge and instruction-following capabilities.
- 100 billion-plus parameter models possess rich knowledge and complex reasoning skills, suitable for deep knowledge tasks.
- Empirical Approach to Development:
- LLM development is experimental, suggesting the testing of various models to find the best fit for specific applications.
- Closed-source vs. Open-source Models:
- Closed-source models, accessible via cloud interfaces, are easy to integrate but pose a risk of vendor lock-in.
- Open-source models offer full control, data privacy, and the ability to run on-premises, suitable for sensitive applications like those involving patient records.
- Choosing an LLM:
- Decisions between using large, closed-source models for their power and cost-effectiveness, or open-source models for control and privacy.
- Encourages testing multiple models to determine the most effective for the application’s needs.
- Note, sensitive data most often should not or cannot be uploaded to the cloud provider. An option is to use an open source model to run on a computer to guarantee privacy of data.
- Model Size as a Performance Indicator:
- How LLMs follow instructions: Instruction tuning and RLHF (optional)
- Instruction Tuning and RLHF Techniques:
- Instruction tuning fine-tunes LLMs on examples of good responses to enable them to follow instructions rather than just predict the next word.
- Reinforcement Learning from Human Feedback (RLHF) further improves LLM outputs to be more helpful, honest, and harmless by rating responses and using those ratings to guide learning.
- Instruction Tuning and RLHF Techniques:
- Pretrained LLMs:
- Often pretrained by large companies using extensive internet text data.
- Pretraining is costly, making it generally impractical for specific applications without significant resources.
- When to Pretrain Your Own Model:
- Advised against due to high costs unless there’s access to a vast amount of specialized domain data, such as Bloomberg’s financial services-focused BloombergGPT.
- Using Existing Models:
- For most applications, starting with an open-sourced, general-purpose LLM and fine-tuning it with your own data is more economical and practical.
- Open Source vs. Closed Source Models:
- Closed-source models offer easy integration and are often inexpensive to run but pose a risk of vendor lock-in.
- Open-source models provide full control and are preferable for applications requiring data privacy, like handling electronic health records.
- Choosing an LLM:
- Model size indicates capability, with larger models possessing richer knowledge and reasoning abilities.
- The choice between open-source and closed-source depends on specific application needs, including control, cost, and data privacy concerns.
- Empirical Development Process:
- Development with LLMs is experimental, suggesting testing various models to find the best fit for your application.
- RLHF (reinforcement learning from human feedback)
- Many companies want the answers to be HHH i.e Helpful, honest, harmless. How can we do that?
- Step 1: Train an answer quality model. Use supervised learning to rate the answers of LLM, e.g “ I’m happy to help, here are some steps…” or “Why bother doing this?!”, the humans would score these answers accordingly. Helpful can be a higher score.
- Step 2: LLM continue to generate a lot of answers to different prompts, and have this AI model score every single response, so we can tune the LLM to generate more responses with higher scores.
- The scores correspond to the scores i.e reward.
- By having the LLM learn to generate answers that merit higher scores or higher rewards or higher reinforcements, the LLM automatically learns to generate responses that are more helpful, honest, and harmless.
- Tool use and agents
- LLMs Using Tools:
- LLMs can trigger actions in software applications, such as placing food orders, by generating specific output commands.
- User verification dialogs are recommended for confirming actions due to the potential for errors in LLM outputs.
- Reasoning with Tools:
- LLMs can extend their reasoning capabilities by calling external tools, like calculators, to perform precise calculations or actions.
- Agents and Advanced AI Research:
- Beyond using single tools, researchers are exploring agents that can execute complex sequences of actions based on reasoning.
- This cutting-edge research aims to enable LLMs to autonomously perform tasks like researching competitors by integrating web search, site visits, and summarization.
- Instruction Tuning and RLHF:
- Techniques like instruction tuning and Reinforcement Learning from Human Feedback (RLHF) improve LLMs’ ability to follow instructions and generate safer outputs.
- Considerations for Tool Use:
- Designers must ensure tools triggered by LLMs do not cause harm or irreversible damage.
- Experimental State of Agents:
- The technology for AI agents is still experimental and not yet reliable for important applications.
- LLMs Using Tools:
- Generative AI in Business:
- Exploring the role of generative AI in enhancing business operations and its broader impact on society, particularly jobs.
- Highlighting the accessibility of generative AI through web user interfaces for various job roles.
- Applications of LLMs:
- LLMs serve as writing assistants or copy editors, useful for drafting professional business reports.
- Marketers utilize LLMs for brainstorming email campaigns to engage lost users.
- Recruiters leverage LLMs for summarizing job candidate reviews.
- Software engineers use LLMs for drafting initial code, although outputs may require debugging.
- Generative AI as a General Purpose Technology:
- Its versatility is underscored by its adoption across diverse job functions to aid in creative thinking, idea generation, and task execution.
- Systematic Framework for Identifying Opportunities:
- Introduction to a systematic approach for analyzing business processes to pinpoint where generative AI can augment or automate tasks, potentially adding value to the business.
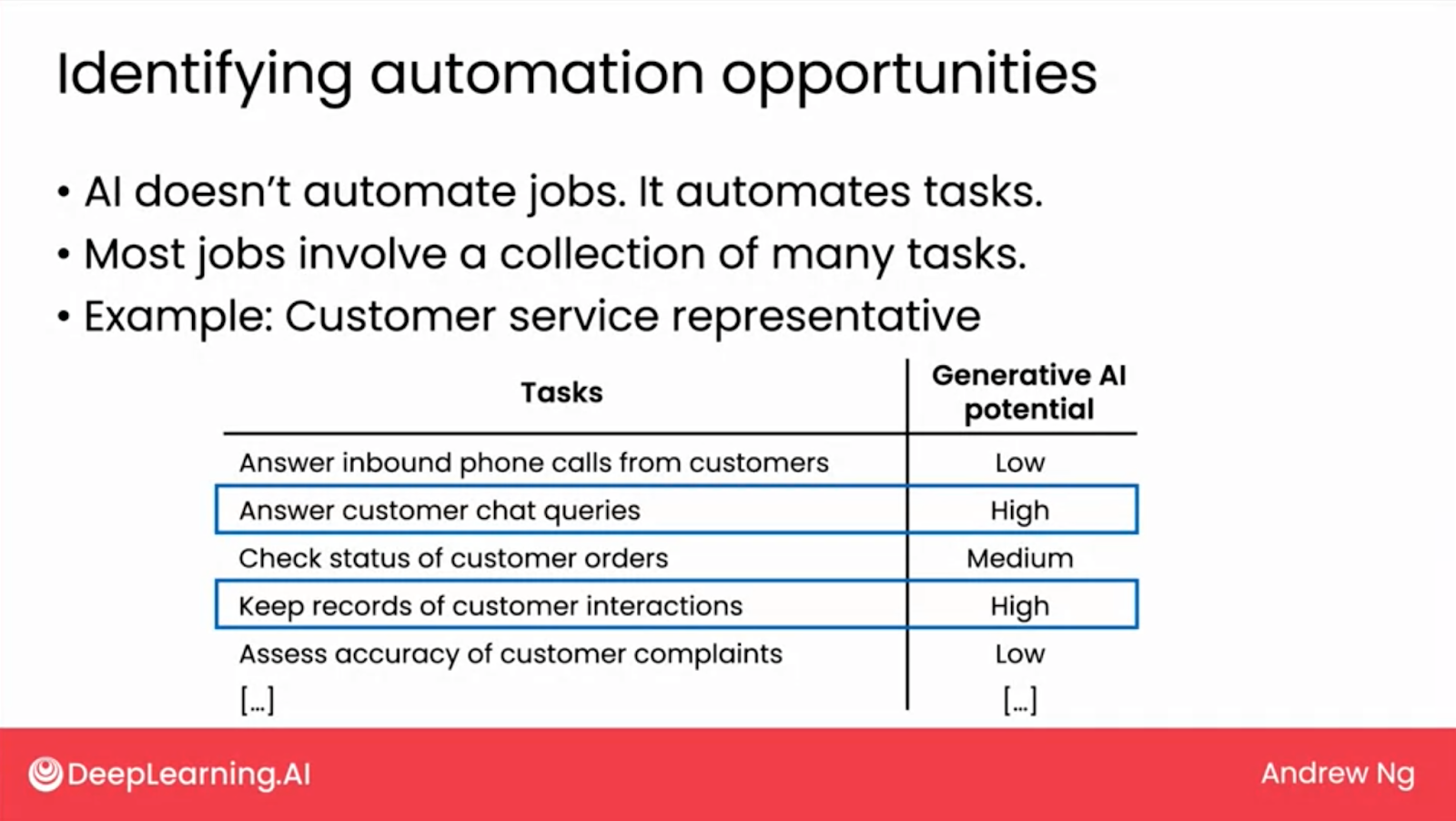
- AI does not automate jobs, it automates tasks. A job involves a collection of tasks. Understand what tasks a job involves will help to determine the potential of generative AI.
- Augmentation can be helping humans with a task or recommend a response. Companies can start here, and once you trust the system, you can automate it.
- For example automation can be to automatically do a task i.e transcribe
- How do you evaluate the potential of generative AI for a task? It depends on technical feasibility and business value.
- Technical feasibility: Can AI do it How costly is it?
- Ask yourself if a fresh college graduate can follow the instructions in a prompt to complete the task
- To quickly assess: Try prompting an LLM to see if you can get it to do it
- An AI engineer can help assess if other techniques including RAG, fine tuning can help
- Business value: How valuable is it for AI to augment or automate this task?
- Is there much time spent on this task?
- Does doing it faster, cheaper or more consistently create substantial value?
- Reevaluating Iconic Job Tasks for AI Opportunities:
- Common perception often focuses on the most iconic task of a job when considering AI automation.
- Systematic analysis of all tasks within a job may reveal unexpected opportunities for generative AI application.
- Examples of Task Analysis in Various Professions:
- Computer Programmers: Beyond writing code, tasks like writing documentation and responding to support requests may be more amenable to generative AI assistance.
- Lawyers: Drafting and reviewing legal documents and interpreting laws have high potential for generative AI, unlike representing clients in court.
- Landscapers: Tasks are less likely to be impacted by generative AI due to the physical nature of the work.
- Systematic Evaluation of Tasks:
- Breaking down jobs into individual tasks and assessing each for generative AI potential based on technical feasibility and business value.
- Augmentation vs. Automation:
- Augmentation involves using AI to assist with tasks, while automation involves AI fully taking over tasks.
- Initial focus on augmentation can gradually shift towards automation as confidence in AI’s outputs grows.
- Beyond Cost Savings:
- While automation often aims at cost savings, the potential for revenue growth and workflow innovation may offer more significant opportunities.
- Examples include enhancing customer service by leveraging AI to respond to queries more efficiently.
- Growth Opportunities:
- Automation and AI can enable businesses to rethink how they create value, potentially leading to new services or improvements in customer experience beyond mere cost reduction.
- In most of technology innovation, going back all the way the invention of the steam engine, to electricity, to the computer. Many companies started off thinking about cost savings but ended up actually putting even more of their effort into pursuing revenue growth. And that’s because growth has no limit, but you can only save so much money. And when certain tasks are automated, it turns out sometimes you can rethink the workflow of how the business creates value. So, for example, if you could do something 1,000 times cheaper because of automation, say, answering queries from customers. Then rather than just taking the cost savings, you may be able to build a new type of customer service organisation that serves people 1,000 times better.
- New workflows and new opportunities
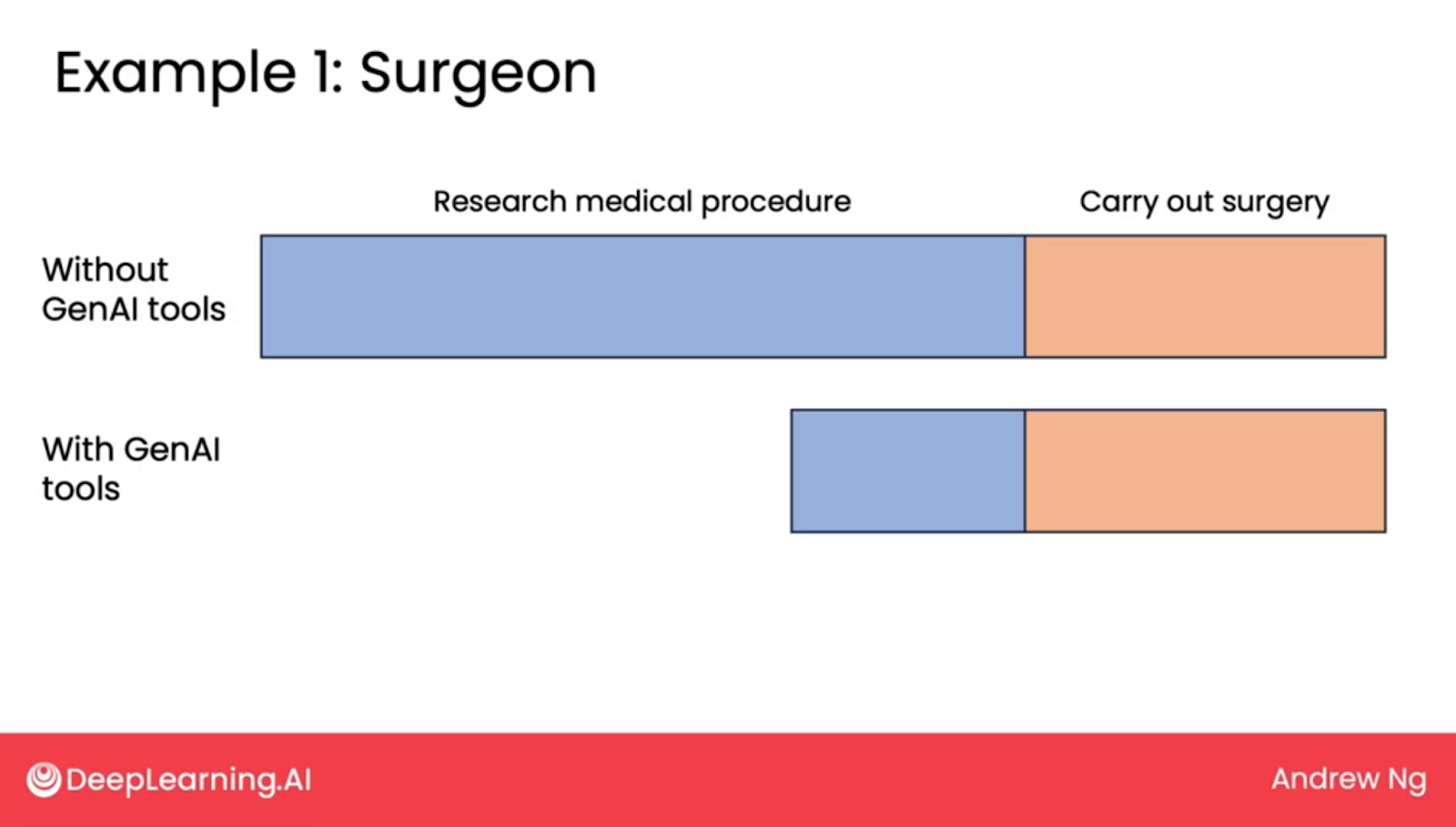
- Research for a medical professional can be shortened during their research phase, but the carrying out of the task will be the same.
- Try it out for your job.
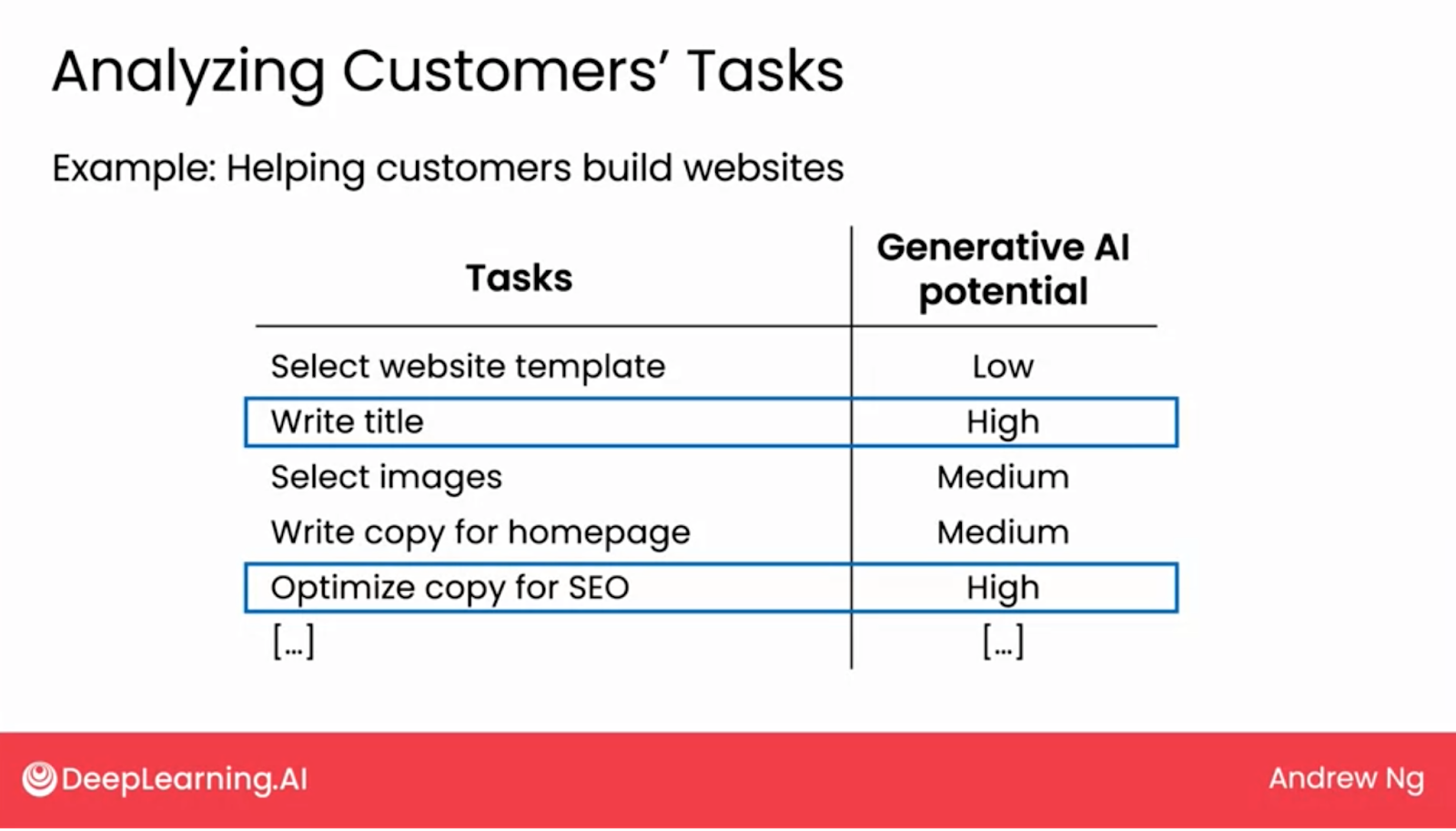
- Alternative idea: Rather than focus on the tasks your employees do, consider the tasks the customers have to do.
- Teams to build generative AI software
- Common Roles for Building Generative AI Applications:
- Software Engineer: Primarily writes the software application, ensuring its robust operation. Beneficial for them to learn the basics of LLMs and prompting.
- Machine Learning Engineer: Implements the AI system, with a focus on learning about LLMs and advanced techniques like RAG (Retrieval Augmented Generation) and fine-tuning.
- Product Manager: Identifies and scopes the project, ensuring the final product meets customer needs. Plays a crucial role in guiding the project towards success.
- Myth of the Prompt Engineer Role:
- Media hype suggested a new, lucrative job role focused solely on writing prompts for LLMs. In reality, these positions are scarce and often require a broader skill set akin to machine learning engineering, debunking the notion of prompt engineering as a standalone profession.
- Team Configurations for LLM Projects:
- Projects can start with a small team or even a single individual who is either a software engineer or a machine learning engineer with some understanding of prompting.
- Common configurations for two-person teams include a combination of a machine learning engineer and a software engineer or a software engineer and a product manager.
- Roles in Larger Teams:
- In more extensive setups, roles like data engineer (managing data quality and security), data scientist (analyzing data for business insights), project manager (coordinating execution), and machine learning researcher (developing or adapting AI technologies) become relevant.
- Accessibility and Lowered Barriers:
- Generative AI has made it easier and less costly to build AI-based applications, encouraging teams to experiment and prototype with even basic knowledge and resources.
- Future Directions:
- The course will next explore how AI is reshaping various job roles and industry sectors, aiming to provide a comprehensive analysis of AI’s broader impacts on the workforce and economy.
- Automation potential across sectors
- Study by Eloundou and Others: Examined how different job occupations are exposed to AI augmentation or automation, finding that higher wage jobs are more exposed to AI than lower wage jobs. This contrasts with earlier automation trends that targeted lower wage, routine tasks.
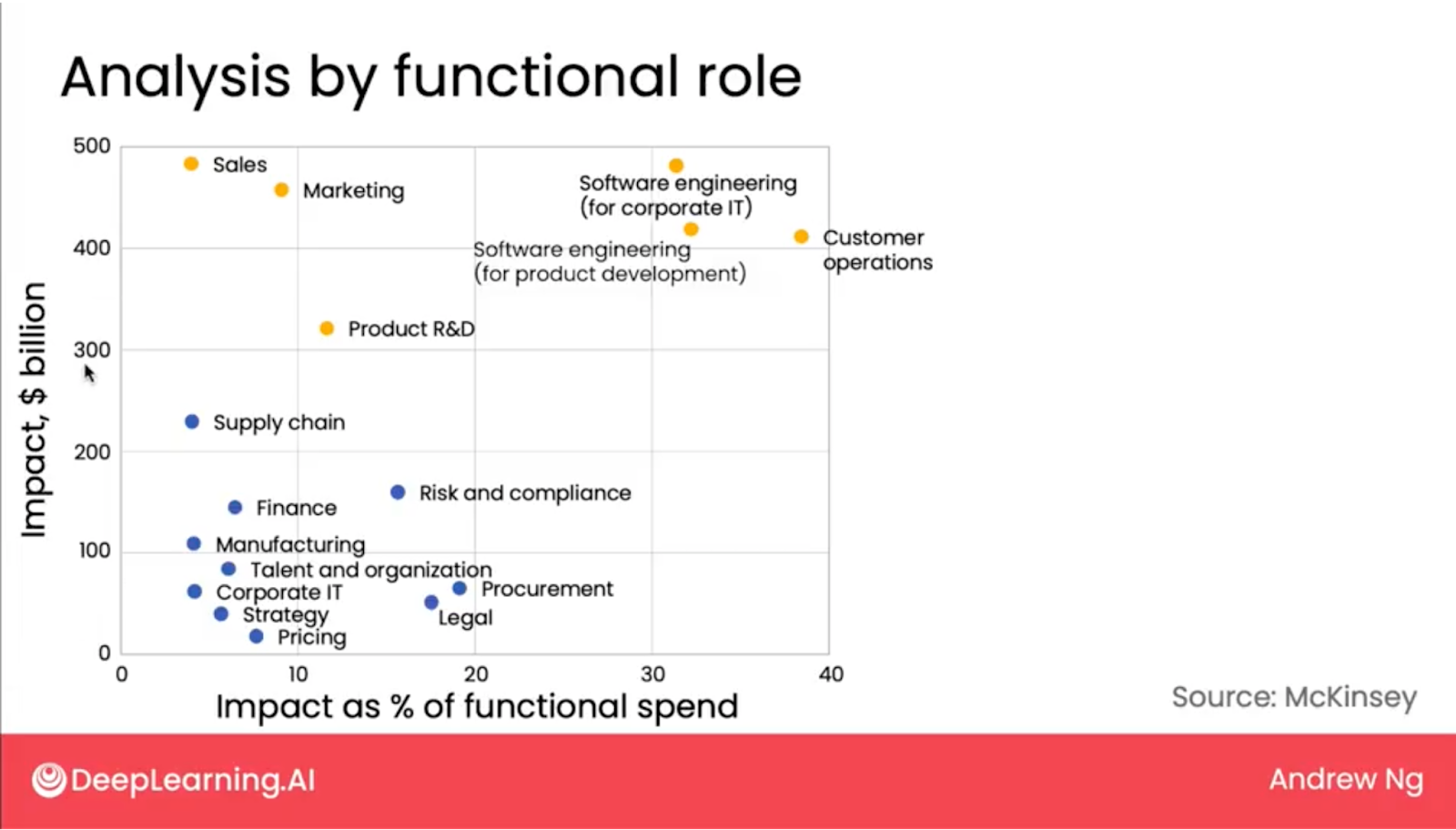
- McKinsey Study on Functional Impact: Analyzed the impact of generative AI across different functional roles, suggesting significant impacts in terms of billions of dollars, particularly in customer operations, sales, and marketing. The study highlights functions and sectors where generative AI’s impact on automation will be substantial, both in absolute terms and as a percentage of functional spend.
- Impact by Industry Sector: McKinsey’s analysis on the impact of AI automation, with a focus on the effects of generative AI, shows that education, legal professions, and STEM fields are among those significantly affected. This indicates a shift towards the automation or augmentation of knowledge work, differing from the automation of physical tasks.
- Knowledge Workers’ Impact: The studies suggest a significant impact of generative AI on knowledge workers, whose value comes from expertise, critical thinking, and interpersonal skills, marking a shift from the automation of manual tasks to those requiring knowledge and intellectual skills.
- Generative AI and Society: The potential societal impact of generative AI raises questions and concerns about the future role of AI in the workforce and society. The document concludes with a segue into discussing the broader societal impacts of AI, including risk mitigation and the development of beneficial, responsible AI technologies.
- Knowledge workers are most impacted.
- Concerns about AI
- Amplification of Humanity’s Worst Impulses: Concerns exist that AI, particularly LLMs trained on internet data, might reflect and amplify humanity’s biases, prejudices, and negative qualities. Examples include gender biases in job roles.
- Mitigating Bias with RLHF: Reinforcement Learning from Human Feedback (RLHF) is employed to make LLMs less biased. It involves training an answer quality model to score responses based on human preferences, leading to outputs that are more aligned with desirable human values.
- AI and Job Displacement: There’s widespread concern about AI replacing human jobs, particularly in fields like radiology. However, the comprehensive role of professionals like radiologists, encompassing multiple tasks, makes complete job automation unlikely in the near term.
- AI as an Augmentation Tool: AI is seen more as a tool for augmentation rather than replacement, with professionals using AI expected to outperform those who don’t. The technology is anticipated to create more jobs than it displaces, focusing on growth over cost savings.
- Existential Risks of AI: Fears persist that AI could cause human extinction, either through misuse by bad actors or unintended consequences. However, concrete scenarios or mechanisms for such outcomes remain speculative.
- Humanity’s Experience with Control: History shows humanity’s capability to manage entities and technologies far more powerful than individuals, suggesting that similar approaches can ensure AI’s safe and beneficial use.
- AI’s Role in Addressing Global Challenges: AI is viewed as a critical asset in tackling significant global challenges like climate change, pandemics, and other existential risks, potentially increasing humanity’s survival and prosperity chances.
- Uncertainty Around AGI: The rapid advancement of AI fuels uncertainty about its future capabilities, particularly concerning the development of Artificial General Intelligence (AGI) and its implications for society and the workforce.
- Artificial General Intelligence (AGI)
- AGI Defined: Artificial General Intelligence (AGI) is AI that can perform any intellectual task a human can. This includes learning to drive a car with minimal practice, completing PhD-level research, or performing the full range of tasks of a computer programmer or other knowledge workers.
- General Purpose Technology vs. AGI: While AI is a general-purpose technology useful for many tasks, it’s distinct from AGI. Large language models like ChatGPT feel general-purpose but do not equate to AGI.
- Current State of AGI: We are still many decades away from achieving AGI, with significant technical breakthroughs needed. Some businesses have offered optimistic forecasts by redefining AGI, but these do not meet the widely accepted definition.
- AI as a Reasoning Engine: Current large language models begin to outline what AGI could eventually look like, using them as reasoning engines for complex tasks.
- Comparison with Human Intelligence: AI’s development path is distinct from human or biological intelligence, excelling in some areas but not yet capable of matching the full range of human intellectual tasks.
- Future of AGI: There’s no fundamental physical law preventing the creation of AGI, which could greatly benefit society, but achieving it remains a challenging goal.
- Responsible AI
- Responsible AI Importance: Developing and using AI ethically, trustworthily, and in socially responsible ways is crucial, with significant progress made through attention and efforts globally.
- Key Dimensions of Responsible AI:
- Fairness: AI should not amplify biases.
- Transparency: AI systems and decisions should be understandable.
- Privacy: User data must be protected and confidential.
- Security: AI systems need protection from malicious attacks.
- Ethical Use: AI should be used for beneficial purposes only.
- Implementation Challenges: The principles of responsible AI can be complex to implement, such as the ongoing debate over what constitutes ethical behavior.
- Emerging Best Practices for Responsible AI:
- Cultivate a Culture of Ethical Discussion: Encourage open debate on ethical issues within teams.
- Brainstorm Potential Issues: Proactively identify and mitigate possible problems related to fairness, transparency, privacy, security, and ethical use.
- Work with Diverse Teams: Include perspectives from all stakeholders impacted by AI to make better-informed decisions.
- Industry-Specific Practices: Certain industries may have unique best practices for responsible AI that are worth consulting.
- Personal Experience and Advice: The speaker shares experiences of consulting diverse perspectives for better project outcomes and the ethical consideration in project selection, emphasizing the importance of working only on projects believed to be ethical and beneficial.
- Building a more intelligent world
- AI’s Potential to Enhance Decision Making: Intelligence, defined as the ability to apply knowledge and skills for good decisions, is crucial. Human intelligence development is costly, limiting access to specialized expertise to the wealthiest.
- Democratizing Intelligence with AI: Artificial intelligence offers the potential to make intelligence accessible and affordable for everyone, transforming the availability of expert advice and education.
- Comparing AI to Electricity: AI’s transformative potential is likened to electricity, revolutionizing industries and human life despite initial fears and dangers associated with new technologies.
- Rapid Improvement and Broad Applications: Generative AI represents a significant advancement, with ongoing improvements expanding its capabilities and use cases for a positive impact on society.
- AI as a Tool for Addressing Global Challenges: AI’s role in tackling significant issues like climate change and pandemics is emphasized, highlighting the necessity of leveraging all available intelligence, including AI.
- Concluding Thoughts and Gratitude: The speaker expresses hope that learners will find generative AI useful and employ it responsibly to enhance their lives and those of others, contributing to a smarter, better world for all.
- Serves a wide range of tasks beyond a single application, making its utility expansive.
Reading suggestions
This is a list of links suggested for further reading:
- McKinsey: The economic potential of generative AI: The next productivity frontier, McKinsey Digital report, June 2023
- GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models, Tyna Eloundou, Sam Manning, Pamela Miskin, and Daniel Rock, March 2023 (arXiv:2303.10130)
- Goldman Sachs: The Potentially Large Effects of Artificial Intelligence on Economic Growth, Joseph Briggs and Devesh Kodnani, March 2023